
Hinter den Kulissen beschäftigt uns seit einiger Zeit eine wichtige Frage: Was macht gute KI-Unterstützung in kollaborativer Wissensarbeit eigentlich aus? Diese Frage treibt uns um, weil wir aktuell KI-Funktionen für samarbeid entwickeln. Einen Einblick in unsere aktuelle Arbeit dazu gibt ein kürzlich veröffentlichter Fachbeitrag. In „Towards an Evaluation Framework for RAG-Based Assistance Systems in Collaborative Design Processes“ – veröffentlicht beim AI-HCD Symposium 2026 in Dresden – stellen wir die Frage: Was macht eine gute KI-Antwort aus? Und: Woran merken wir, ob eine KI-gestützte Zusammenarbeit wirklich gut funktioniert – oder ob sie nur gut aussieht?
Das Problem mit den üblichen Metriken
KI-Systeme, die auf dem Prinzip des sogenannten Retrieval-Augmented Generation (RAG) basieren, verbinden große Sprachmodelle mit eigenem Wissen aus einer Wissensbasis – zum Beispiel Projektdokumenten, Nutzungsforschung oder früheren Entscheidungen. Solche Systeme werden heute immer häufiger in kreativen und kollaborativen Arbeitsprozessen eingesetzt. Und auch die KI-Unterstützzung in samarbeid ist ein RAG-Ansatz.
Bisherige Bewertungsansätze messen vor allem technische Qualität: Ist die Antwort relevant? Stimmt sie mit dem Quellmaterial überein? Das sind wichtige Fragen – aber sie reichen nicht aus. Denn ein System kann technisch einwandfrei funktionieren und trotzdem schleichend etwas Entscheidendes untergraben: die Handlungsfähigkeit und Kontrolle der Menschen, die damit arbeiten.
Drei Schichten, eine entscheidende Frage
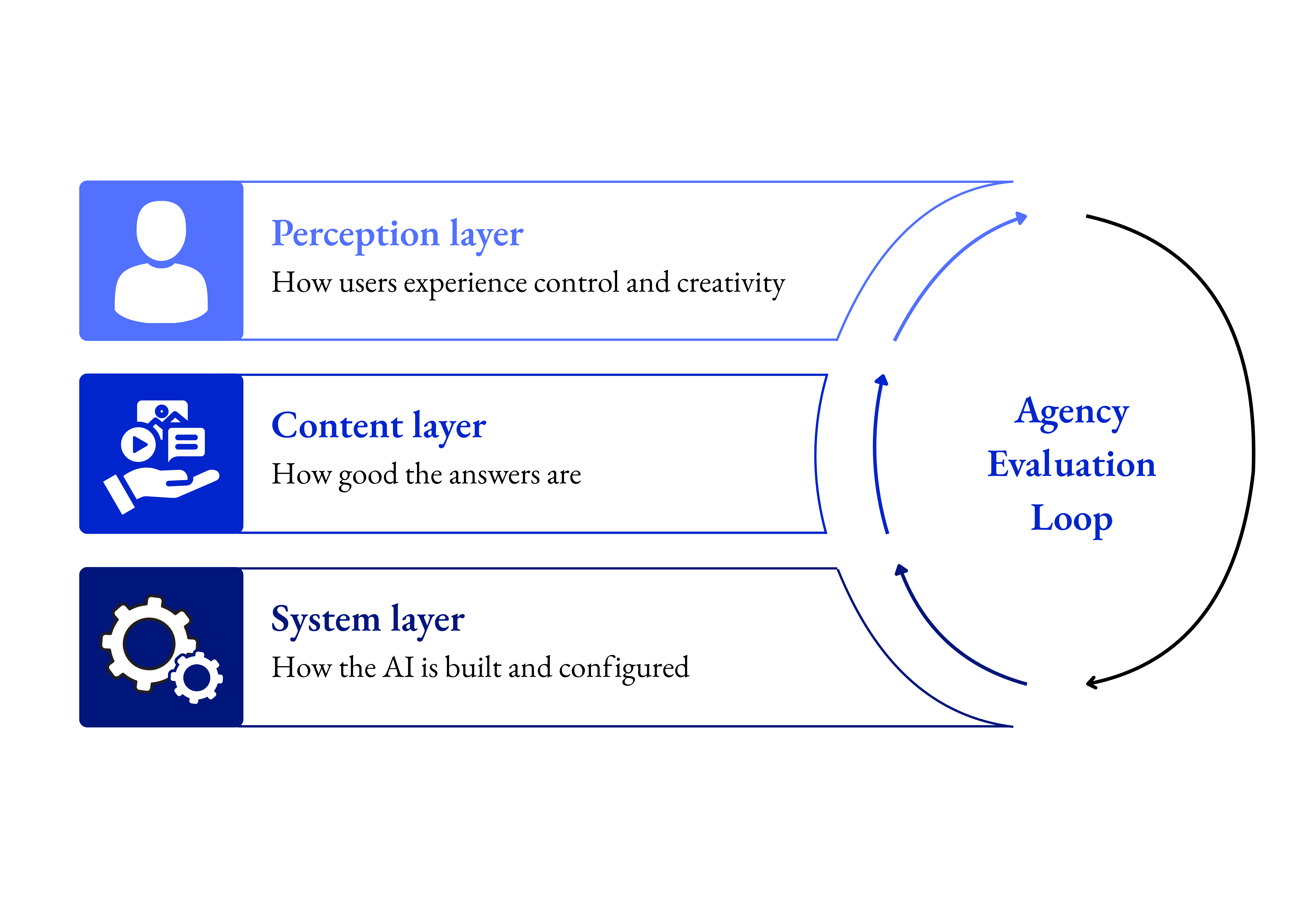
Unser Paper schlägt ein Drei-Schichten-Modell vor, das diese Lücke schließt. Es verbindet die technische Konfiguration eines RAG-Systems (Systemschicht) mit der inhaltlichen Qualität seiner Ausgaben (Inhaltsschicht) und – neu – der Wahrnehmungsebene: Erleben die Menschen, die mit dem System arbeiten, noch echte Entscheidungsautorität? Behalten sie das Gefühl, Probleme selbst zu definieren und Ideen wirklich selbst zu entwickeln?
Diese erlebte Handlungsfähigkeit (Human Agency) ist keine Nebensache. Wer KI-Effizienz will, muss Agency messen – denn Systeme, die Entscheidungen scheinbar vorwegnehmen oder Lösungsräume erschöpfend abbilden, können genau das systematisch untergraben, ohne dass es in klassischen Metriken sichtbar wird.
Was das für samarbeid bedeutet
samarbeid ist unser empirisches Forschungsfeld für genau diese Fragen. Wir integrieren KI-Funktionen in samarbeid – für gemeinnützige Organisationen und Sozialeinrichtungen, in denen Entscheidungsqualität, geteilte Verantwortung und echte Zusammenarbeit keine abstrakten Werte sind, sondern täglich zählen. Dass wir dabei von Anfang an wissen wollen, wie sich KI auf die Handlungsfähigkeit der Teams auswirkt, ist kein Zufall: Es ist der Kern unseres Forschungsansatzes.
Unser Paper liefert dafür das konzeptuelle Fundament: Es beschreibt drei prototypische KI-Ausgabeprofile – The Craftsperson (präzise und quelltreu), The Provocateur (explorativ und offen) und The Architect (umfassend und konvergierend) – und macht damit greifbar, wie unterschiedliche Systemkonfigurationen das Erleben von Teamarbeit verändern können. Eine Pilotstudie, die diese Zusammenhänge empirisch untersucht, ist in Vorbereitung.
Das vollständige Paper ist hier verfügbar (Open Access).
Bitte zitiert unseren Beitrag folgendermaßen:
Reichardt, L., Prilop, M., Maicher, L. (2026): Towards an Evaluation Framework for RAG-Based Assistance Systems in Collaborative Design Processes: A Work in Progress Paper. Proc. 1st Symposium on Artificial Intelligence throughout the Human-Centered Design Process. DOI: 10.18420/AIHCD2026_011. Gesellschaft für Informatik e.V.. Dresden. 23.04.2026